
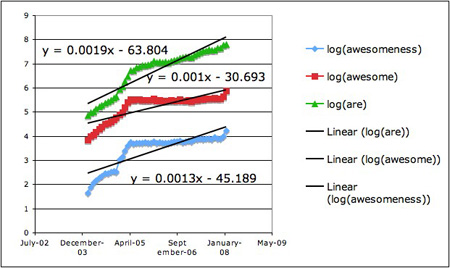
Figure 1. Frequency from 2/2004 to 2/2008
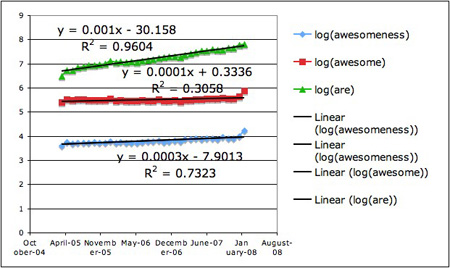
Figure 2. Frequency from 4/2005 to 2/2008
Every once in a while, I get the inclination to try to do a little math. It’s a dangerous endeavor, but sometimes I can’t help myself. But before I get ahead of myself, I should give a little back ground.
Sometimes you learn a word and all of the sudden you see it everywhere. The nagging question is, was is always being used and you just glossed over it, or is there a change in the frequency of its use? You discovered the word precisely because it was starting to be used for more often.
Not too long ago, I found the word “awesomeness” entering my general vocabulary to signify great approval. Awesomeness feels fresh, a slight tweak on the new vintage “awesome” from the 80s, a personally influential era. However, in the past week, I’ve seen the word Awesomeness appear in a lot of places, from friends and strangers alike. I started thinking if the word has gaining traction in the public at large, so last weekend I started the quest to figure out ways to capture the growing use of the word.
Word frequency counts is nothing new. Media studies have been doing this type of research in newspaper and magazines for decades. However, it is becoming much more democratic, mostly because of the decreasing cost of computing and the related increase span of the web, which has been collecting data much easier. I decided to use the blogosphere because it seems like a pretty good proxy for general language usage. As well, the Google blog search feature allows you do set the dates for your search. Of course there are drawbacks to uses the word count of Goggle, including that the blogosphere is a obviously a subset of general usage and also because I have no idea how Goggle tracking and tallying the blogs it is indexing. Nevertheless, I can live with the approximation, given that the only cost for retrieving the data is bandwidth and time.
I searched for “awesome,” “awesomeness,” and “are” for each month from February 2004 to February 2008.
The word “are” was used as a control of sorts. Because the blogosphere itself it constantly growing, the number of times a word appears in a given month is expected to increase. Using an often used word such as “are” can be a proxy of the overall growth of the blogosphere. One could not expect the rate of the word “are” to fluctuate greater from month to month. Any true increase of the word usage would have to outpace the growth rate of “are.”
I also tracked the usage of the root word “awesome” for a couple of reasons. Sometimes search engines clump different variations of the same root word together in its search results. I wanted to check to see that “awesomeness” wasn’t being put together with “awesome.” The two are also an interesting comparison. If both increased at similar rates, then maybe what I am seeing is just an overall revival of 80s idioms. However, if “awesomeness” is also increasing at a great rate than “awesome” my original suspicions would be validated.
In the short time I started on this little math adventure, the word kept on appearing, and in the write up of my findings, I came across the the ultimate reference, apparently a website which declared March 10 (last week) International Day of Awesomeness.
Just looking at the words appearance in the past two full months, this is what I found:
February-2008: Awesomeness: 17,182 ; Awesome: 736,783 ; Are: 61,531,049
January-2008: Awesomeness: 9,627 ; Awesome: 429,769; Are: 57,214,958
There is clear jump in the past two months, but what does that jump mean, if the total number of blog pages continues to grow? Both Awesomeness and Awesome almost doubled as compared to Are, but how do you measure the significance of that? Graphing all the frequency of these three words against each other is hard because are orders of magnitude higher then the others. My math coach Pam (yes, I actually call her that) suggested I take the log of my data to make it more comparable. If your recall high school math, log (1,000,000) = 6, log(100,000) = 5, and log(10,000) = 4. Now, if you take the log of all your data points, the curves can fit on a single graph of manageable size. It even gets better, because it translates an exponential curve into linear curve, which makes finding the growth rate (i.e. slope of the curves, which is the rise over run of the function) much easier.
If you look at the two figures, you’ll notice an upwardly trend. There is a peculiar elbow in the spring of 2005, which could be a big spurt of growth or some aberration of Goggle’s indexing. After looking at the first graph, I decided to draw another graph to focus in other growth of all three term’s use in the past year and focus the analysis on that because I wanted to fit a linear line to the curves and removing the bend would give me a closer fit. (Is that cheating?)
I fed the curves into excel to fit linear functions, and can see that Awesomeness has a slope of 0.0003 versus Awesome which has a slope of 0.0001. This is good, because it means Awesomeness is being used at rate that is 3 time more than Awesome. However, Are (our base line) has a slope of 0.001. This is sort of bad, because 80s slang doesn’t seem to be outpacing the general growth of blogs, which I was hoping to see.
I’m not sure what to make of it, in the end. However, it does have me thinking about blogs from a higher altitude and that math is pretty awesome. Many thanks to Pam and Wojciech who gave me some good nudges. Of course, I’ll take the blame for the conclusions. I’m curious to hear what my math friends say, especially if they find mistakes in my logic. Also, it has taken me much too long to post this, which is why I’m just throwing what I have up. I’ll post any corrections later including typos.



Ray,
There is a lot of awesomeness here. Regarding your conclusions, I think now its time to think about all those yahoos who are spewing blogs. One might think of the index of are to awesome or awesomeness as being influenced by not only the relative uptake of 80s tongue, and its 00s incarnations, but also by the proportion of blog entries that are being created by hipsters versus the vanilla people. So we have a hidden confounder, the hipster blog index. My theory is as blogs are being incorporated into everything from news shows to cousin susie’s wedding, that the proportion of blogs generated by those inclined to use the word awesome or awesomeness is decreasing. So the use of 80s slang may in fact be experiencing a wicked comeback in certain subpopulations who uses blogs, but the general population of bloggers is experiencing a coincident demographic shift that is preventing awesomeness from keeping up with the general growth of blogs.
m.c.p.
This is awesome.
One note that you’ve probably already realized: When you were searching Google you were getting the total number of pages which included the word, not the total number of mentions of the word itself. This becomes a problem when Google groups it’s results from a single site because the most serious purveyors of awesomeness are only getting two pages at most (which I guess may work equally for “are” and therefore cancel each other out.)
Noah: Actually to be truthful, I didn’t know how Google is grouping the pages. But I should have been more clear on differentiating between word frequency and page counts. Glad you liked the post. I’m hoping to do more of these kinds of ad-hoc “studies.”
MCP: Ah… that is interesting. You are quite correct that I was assuming that the demographics of blog writers was increasing at a uniform rate, which you suggest is not true. I am inclined to agree with you. I think the hipster blog index is worth investigating. That “bend” in early 2005 deserves another look. But downloading all the data get time consuming. I think I need an intern, or learn how to write bots.
Well, “are” is a dangerous word to normalize against: it doesn’t control for uneven growth of other languages and spammy pages, it doesn’t control for the context, and so on. Try engaging the http://datamining.typepad.com/ blog via a trackback?
Ray, it is nice to hear that you are studying a word that I’ve never heard of. Even the examples on the web don’t make any sense to me. Am I too old?
It is not so easy to tell that the slopes 0.0001 and 0.0003 are significantly different. I would suggest that you do a regression where the log frequency of awesome is entered as a quadratic term like this
awesomeness ~ awesome + awesome^2
So if awesomeness is growing faster than the awesome, then the quadratic term will be significant. If this doesn’t make sense, I would suggest reading Baayen’s chapter on regression modeling and downloading the R stats package.
http://www.ualberta.ca/~baayen/publications/BaayenCUPstats.pdf
http://cran.r-project.org/
Also, another problem with using “are” as a control is that word frequency is related to word length, so it would be better to control for word length somehow. Maybe you could enter a word of a similar length like “specialness” into the equation.
awesomeness ~ awesome + awesome^2 + specialness
let me know if you need some help with this…
Aleks: Thanks for the link, I will look into it. You raise important point, there is a lot to try to normalize against. I wasn’t that worried about other languages, I’m curious to know how often Are appears in non-English language sties. Your spammy pages point is a good one too. This was a paper napkin calculation, which points to a lot more questions, I not sure I’m quality to answer, but are nevertheless interesting.
To Franklin, my brain just exploded a little bit. But I’m amazed at how subtle this growth is to capture.
And to everyone nice enough to read this post and also comment. Your awesomeness is undeniable.
Hi all,
My response has been a bit delayed due to some travel to a no internet zone.
Quick thoughts: I actually would not consider quadratic growth, since the line fit so well to the log(frequency). This is strongly suggestive that the growth is close to exponetial and not quadratic. At least over the times considered. Exponential may also make more sense as a growth model in. Re: the slope differences, there is a statistical test that could be done here….
Regarding what word to normalize against. The key factor is not length for that comparison word. How often the comparison word is being used is not the relevant quantity. The quantitiy of interst is really the change over time. This is exacly what the slope gives you. The intercept is absorbing some of the absolute differences in useage (specifically the difference at time 0).
For this effort, what you care about for an index word is that the rate of usuage for that word (number per blog or per page or whatever Ray is counting) is fairly stable for the time considered. So a basic connector word is a good idea. Somthing inert that wouldnt flare up due to a news story, like the word mortgage over the last few years. A linguist may have more thoughts on this. Articles in general may be experiencing declines. Good grammer and a word like “are” may also be experienceing changes (declines) in usuage. But if these changes are happening at a rate that is much slower than the rate of a trendy word like awesomeness than I think it still makes a decent comparator.
Awesome post! I’ve been meaning to reply for forever, so apologies for the delay.
Regarding Pam’s last comment — I think one way to test how proper writing techniques are being used is comparing the growth in commonly misspelled words (e.g. http://en.wikipedia.org/wiki/Wikipedia:Lists_of_common_misspellings/).
For example, look at “believe” versus “beleive” at Google Trends (sorry, my web analytics aren’t as fancy as yours 🙂 ): http://www.google.com/trends?q=believe%2C+beleive&ctab=0&geo=all&date=all&sort=0 Notice the weird drop in “beleive” back in 2004? Weird… I’m trying to find some long term patterns but am not being very successful… Regardless, this could be a good proxy for grammar or “proper spelling”.
Are you still playing around with this?